Аналитика данных всегда сводится к цифрам, что не всегда интуитивно понятно для мира IT-администрирования. Мы умеем работать с числами, и можно ожидать, что будет проведено множество научных исследований, посвященных выявлению взаимосвязей и знаний в числовых данных. Однако наши системные журналы представляют собой строки слов, полные фразы или предложения, которые лишь местами заполнены цифрами.
Ища способ математического анализа текста, команда Energy Logserver использовала технику векторизации. Построение вектора позволяет преобразовать любую строку текста в число. Вооружившись знаниями, полученными благодаря сотрудничеству с профессорами Варшавского технологического университета, мы обратились к библиотеке Word2Vec.
Наша цель — не просто преобразование текста в числа. В рамках текущей разработки мы ищем удобный способ группировки исходных данных. Желаемая кластеризация должна помочь в неуправляемой группировке входных данных. Это облегчит оператору просмотр соответствующих данных.
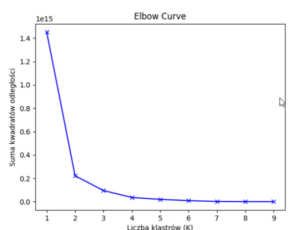
Кластеризации предшествует анализ количества групп, предлагаемых алгоритмом. Для этого используется метод «локтя».
Пример набора векторов:
-0.008289610035717487
0.007978345267474651
-0.006714770570397377
-0.008822474628686905
0.00699368491768837
-0.009639430791139603
Предлагаемое количество групп после векторизации Word2Vec составляет 2-3, что недостаточно. Интуитивно известно, что в данной выборке больше типов событий.Искалась ошибка кластеризации, поэтому после анализа мы вернулись к проблеме векторизации.
В каком-то смысле очевидно, что при неправильном расположении данных их невозможно будет хорошо интерпретировать. Поэтому аналитическая группа протестировала другую библиотеку векторизации — TfidfVectorizer.
После изучения документации и проведения нескольких экспериментов было замечено значительное улучшение результатов.
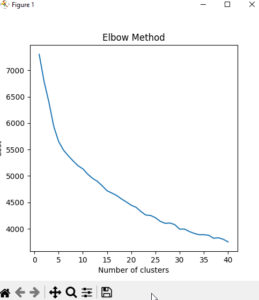
Другой курс показывает, что во входных данных гораздо больше различий и возможных групп.Word2Vec создает векторы на основе контекста, в котором слова встречаются в тексте. Эта модель анализирует контекст слов и затем присваивает каждому слову вектор таким образом, чтобы слова в схожих контекстах имели схожие векторы. Этот метод особенно полезен для моделирования семантики слов, то есть для определения того, какие слова близки друг к другу по смыслу.TfidfVectorizer, напротив, использует векторы с длиной, равной количеству слов в корпусе.
Разный курс показывает, что во входных данных гораздо больше различий и возможных групп.
Word2Vec создает векторы на основе контекста, в котором слова встречаются в тексте.
Эта модель анализирует контекст слов и затем присваивает вектор каждому слову таким образом, чтобы слова в схожих контекстах имели схожие векторы. Этот метод особенно полезен для моделирования семантики слов, то есть для определения того, какие слова близки друг к другу по смыслу.
TfidfVectorizer, напротив, использует векторы с длиной, равной количеству слов в корпусе. Вектор для каждого документа создается на основе частоты встречаемости слов в этом документе и во всем корпусе. Таким образом, векторы для разных документов представляют собой различные комбинации слов. Этот метод особенно полезен при анализе текста для классификации и группировки документов.
Таким образом, Word2Vec используется в основном для моделирования семантики слов, а TfidfVectorizer — для анализа текста с целью классификации и группировки документов.